Deep learning笔记2-CNN卷积神经网络
1. 卷积神经网络简介(CNN)
原图和公式说明来自:零基础入门深度学习(4) - 卷积神经网络
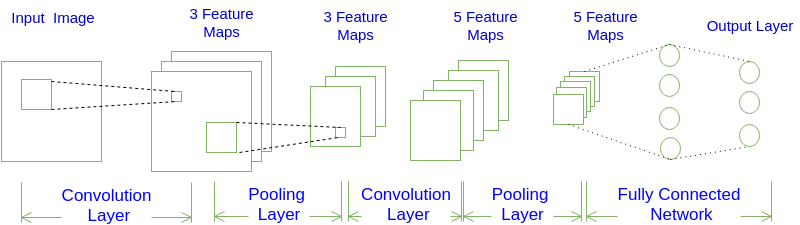
一个卷积神经网络(Convolutional Neural Network)由若干卷积层、池化层、全连接层组成。
1.1. 卷积神经网络输出值的计算
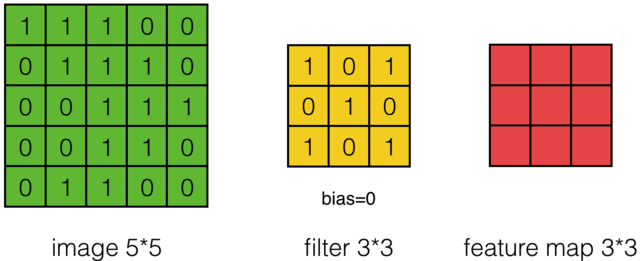
以一个55的图像,使用一个33的filter进行卷积,得到一个3*3的Feature Map为例:
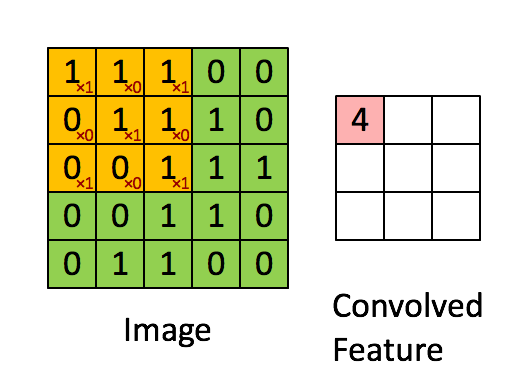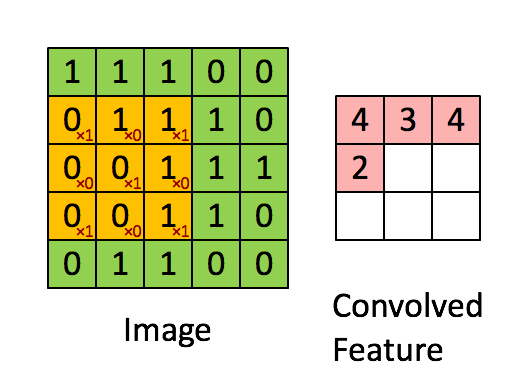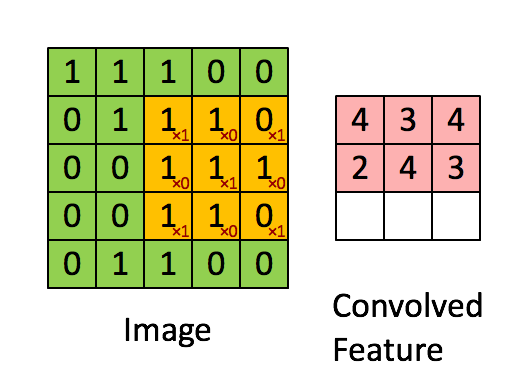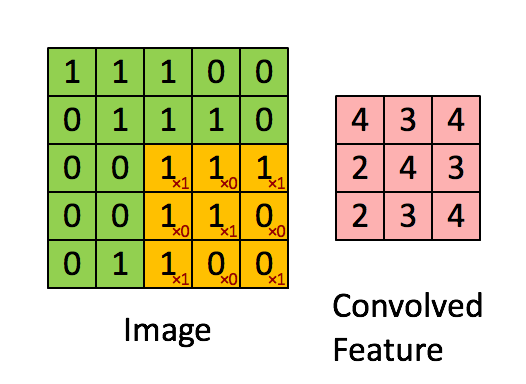
以步幅(stride)为1,依次计算出Feature Map中所有元素的值,计算过程:
用例来自 - 零基础入门深度学习(4) - 卷积神经网络
推荐阅读 - Gluon - 卷积神经网络
1.1.1. 卷积层输出值的计算
图像大小、步幅和卷积后的Feature Map大小,满足下面的关系:
\[\begin{align} W_2 &= (W_1 - F + 2P)/S + 1\qquad\\ H_2 &= (H_1 - F + 2P)/S + 1\qquad \end{align}\]
在上面两个公式中:W2是卷积后Feature Map的宽度;W1是卷积前图像的宽度;F是filter的宽度;P是Zero Padding数量,Zero Padding是指在原始图像周围补几圈0,如果P的值是1,那么就补1圈0;S是步幅;H2是卷积后Feature Map的高度;H1是卷积前图像的宽度。
下面的显示包含两个filter的卷积层的计算。可以看到773输入,经过两个333filter的卷积(步幅为2),得到了332的输出。另外也会看到下图的Zero padding是1,也就是在输入元素的周围补了一圈0。
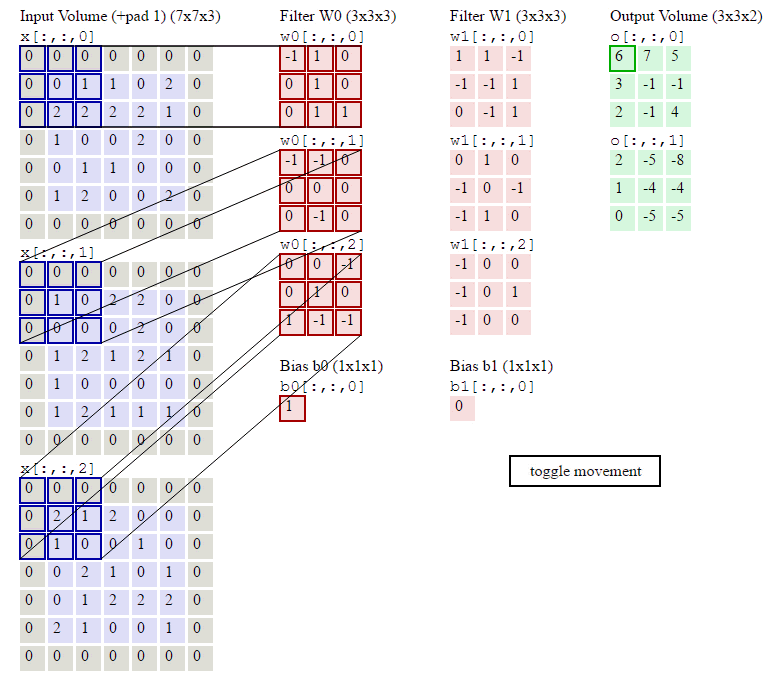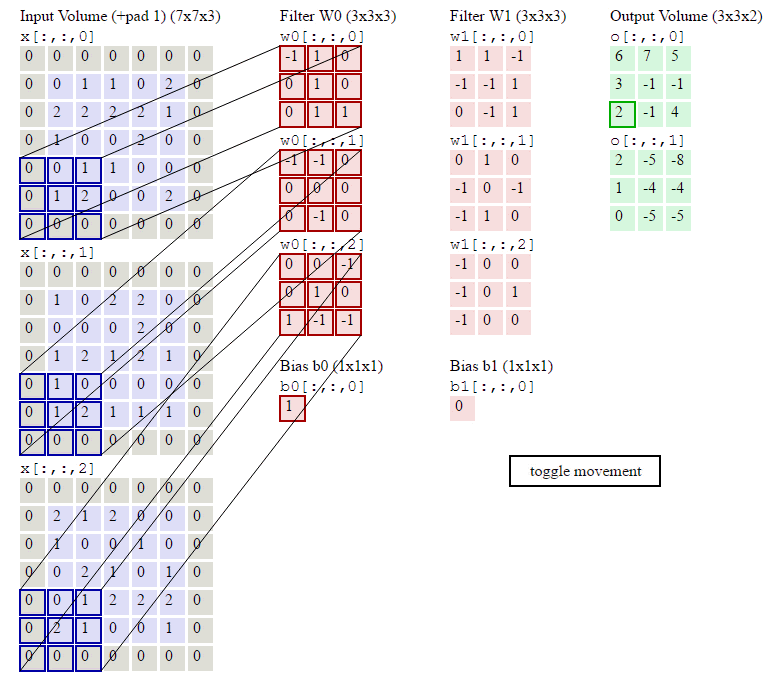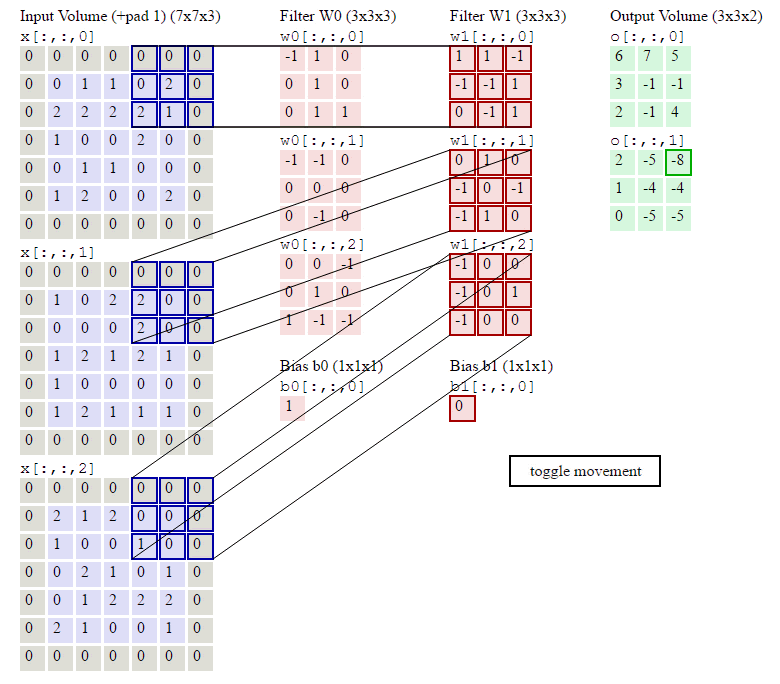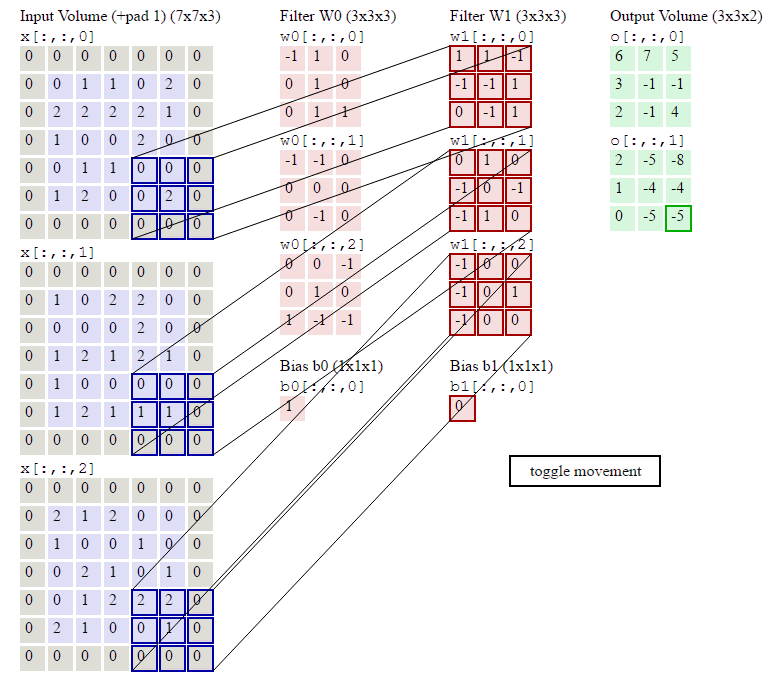
1.1.2. 池化层输出值的计算
池化层主要的作用是下采样,通过去掉Feature Map中不重要的样本,进一步减少参数数量。池化的方法最常用的是Max Pooling,即样本中取最大值,作为采样后的样本值。下例是2*2 max pooling:
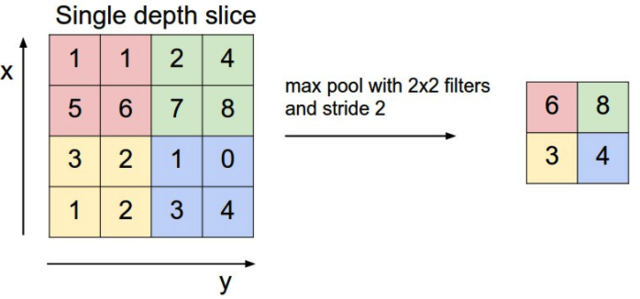
还有Mean Pooling,即取各样本的平均值。
1.2. 卷积公式的计算
用X[i,j]表示图像的第i行第j列元素;对filter的每个权重进行编号,用W[m,n]表示第m行第n列权重,用Wb表示filter的偏置项;对Feature Map的每个元素进行编号,a[i,j]用表示Feature Map的第i行第j列元素;用f表示激活函数。
\[a_{i,j}=f(\sum_{m=0}^{2}\sum_{n=0}^{2}w_{m,n}x_{i+m,j+n}+w_b)\]
深度大于1的卷积计算公式:
\[a_{i,j}=f(\sum_{d=0}^{D-1}\sum_{m=0}^{F-1}\sum_{n=0}^{F-1}w_{d,m,n}x_{d,i+m,j+n}+w_b)\]
1.3. 卷积神经网络的训练
先前向传播,再反向传播,利用链式求导计算损失函数对每个权重的偏导数(梯度),然后再根据梯度下降公式更新权重w
1.4. 关于权重w与偏置项b的初始化
1.4.1. 权重w的初始化
① 均匀分布:tf.random_uniform()
② 正太分布:tf.random_normal()
③ 从截断的正态取值--横轴区间(μ-2σ,μ+2σ)95%面积:tf.truncated_normal()
④ 还有一个经验公式:从[-y, y]取值,其中 \(y=1/\sqrt{n}\)
根据经验使用③效果较佳…
1.4.2. 偏置项b的初始化
一般使用tf.zeros()来初始化为零值.
阅读参考 - Role of Bias in Neural Networks
“a bias value allows you to shift the activation function to the left or right”
2. 基于TensorFlow的实现(CNN with TF)
2.1. TF卷积神经网络的基本实现
2.1.1. 卷积层
1 | |
weights 作为滤波器,[1, 2, 2, 1] 作为 strides。TensorFlow 对每一个 input 维度使用一个单独的 stride 参数,[batch, input_height, input_width, input_channels]。通常把 batch 和 input_channels (strides 序列中的第一个第四个)的 stride 设为 1。
2.1.2. 池化层
1 | |
tf.nn.max_pool() 函数实现最大池化时, ksize参数是滤波器大小,strides参数是步长。2x2 的滤波器配合 2x2 的步长是常用设定。
ksize 和 strides 参数也被构建为四个元素的列表,每个元素对应 input tensor 的一个维度 ([batch, height, width, channels]),对 ksize 和 strides 来说,batch 和 channel 通常都设置成 1。
2.2. TF卷积神经网络的实现例
对 CIFAR-10 数据集 中的图片进行分类。 该数据集包含飞机、猫狗和其他物体。先预处理这些图片,然后用所有样本训练一个卷积神经网络。图片需要标准化(normalized),标签需要采用 one-hot 编码。构建卷积(convolution)、最大池化(max pooling)、丢弃(dropout)和完全连接(fully connected)的层。最后在样本图片上看到神经网络的预测结果。
具体实现不赘述,过程直接看Github,吾辈准确率不高,才57%左右 - Github Link
#### 2.3. 卷积神经网络内部一窥
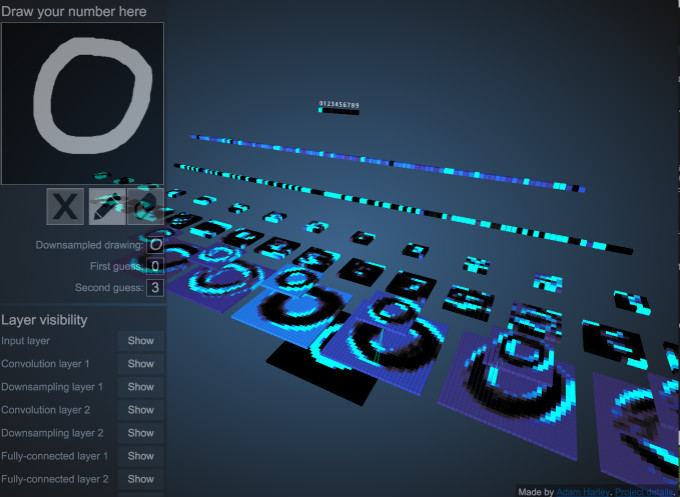
| 瑞尔森大学的Adam Harley创建了一个交互式视觉化模型,能够帮助解释卷积神经网络内部每一层是如何工作的:Link |
| ### 3. 自编码器(Autoencoder) |
| 自编码器(Autoencoder)由于处理过程中有单元减少,解压缩效果不如MP3与JPEG,但是在图像去噪(Denoising)与降维(dimensionality reduction)方面取得不错的效果。 |
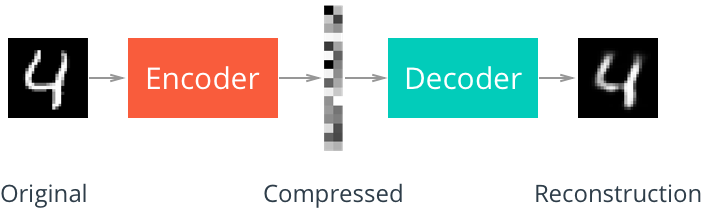 |
3.1. 使用dense实现
Encoder:使用tf.layers.dense与relu激活函数实现 Decoder:使用tf.layers.dense与sigmoid激活函数实现
- Autoencoder用例实现1 - Udacity Github Link
3.2. 使用卷积实现
Encoder:使用tf.layers.conv2d与tf.layers.max_pooling2d(下采样)实现 Decoder:使用tf.layers.conv2d与tf.image.resize_nearest_neighbor(上采样)实现
- Autoencoder用例实现2 - Udacity Github Link
推荐:Deconvolution and Checkerboard Artifacts Distill
4. 迁移学习(Transfer Learning)
迁移学习(Transfer Learning):在实际中,通常会使用预训练模型(比如 AlexNet,VGGNet,Google Inception Net,ResNet),将最后的几个全连接层(基本作用是分类器),替换成自己的分类器,再进行训练与测试。
介绍其中两种CNN网络模型 AlexNet 与 VGGNet:
4.1 AlexNet
AlexNet是由SuperVision设计,包括成员Alex Krizhevsky,Geoffrey Hinton,Ilya Sutskeve设计的CNN网络模型。该模型在2012年ImageNet Large Scale Visual Recognition Challenge的比赛中以15.3%错误率获得冠军,领先第二名10.8个百分点。
输入要求256(图像大小),均值是256的,减均值后再crop到227(输入图像大小)
参考 - AlexNet
4.2 VGGNet
VGGNet是牛津大学计算机视觉组(Visual Geometry Group)和 Google DeepMind 公司的研究员一起研发的的深度卷积神经网络,在ILSVRC 2014上取得了第二名的成绩,将Top-5错误率降到7.3%。
输入要求256(图像大小),均值是256的,减均值后再crop到224(输入图像大小)
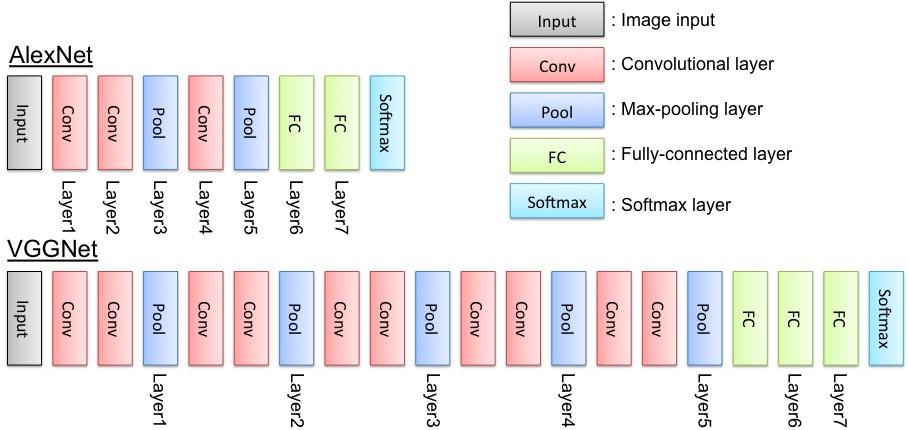
- VGGNet使用例 - Udacity Github Link
5. 目标检测(Object Detection)
Object Detection是在给定的图片中精确找到物体所在位置,并标注出物体的类别。 Object Detection要解决的问题就是物体在哪里Where,是什么What这整个流程的问题。
但是在现实生活中,问题不是那么简单,物体的尺寸变化范围很大,摆放物体的角度,姿态不定,而且可以出现在图片的任何地方,而且物体的类别还有多种。
关于目标检测区域建议的演化历史:- A Brief History of CNNs
CNN->RCNN->Fast-RCNN->Faster-RCNN->Mask-RCNN->...
