Deep learning笔记3-RNN循环神经网络
1. 循环神经网络(RNN)
原图和公式说明来自:零基础入门深度学习(5) - 循环神经网络
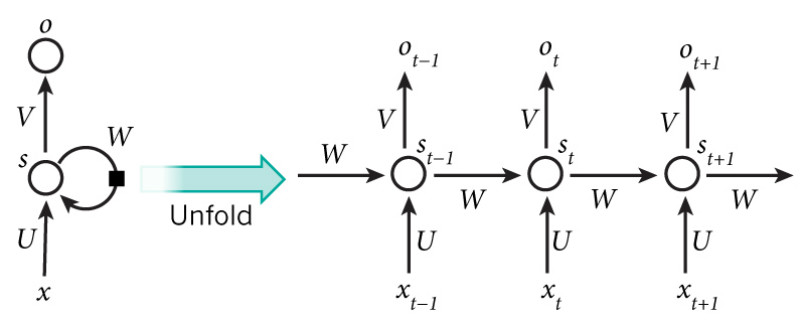
x是一个向量,表示输入层的值(这里面没有画出来表示神经元节点的圆圈);
s是一个向量,表示隐藏层的值(这里隐藏层面画了一个节点,也可以想象这一层其实是多个节点,节点数与向量s的维度相同);
U是输入层到隐藏层的权重矩阵;
o是一个向量,表示输出层的值;
V是隐藏层到输出层的权重矩阵。
W权重矩阵是隐藏层上一次的值作为这一次的输入的权重矩阵。
1.1. 循环神经网络的计算
1.1.1. 基本循环神经网络
\[\begin{align} \mathrm{o}_t&=g(V\mathrm{s}_t)\qquad\qquad\quad(输出层)\\ \mathrm{s}_t&=f(U\mathrm{x}_t+W\mathrm{s}_{t-1})\qquad(隐藏层)\\ \end{align}\]
如果反复把隐藏层带入到输出层得到:
\[\begin{align} \mathrm{o}_t&=g(V\mathrm{s}_t)\\ &=Vf(U\mathrm{x}_t+W\mathrm{s}_{t-1})\\ &=Vf(U\mathrm{x}_t+Wf(U\mathrm{x}_{t-1}+W\mathrm{s}_{t-2}))\\ &=Vf(U\mathrm{x}_t+Wf(U\mathrm{x}_{t-1}+Wf(U\mathrm{x}_{t-2}+W\mathrm{s}_{t-3})))\\ &=Vf(U\mathrm{x}_t+Wf(U\mathrm{x}_{t-1}+Wf(U\mathrm{x}_{t-2}+Wf(U\mathrm{x}_{t-3}+...)))) \end{align}\]
1.1.2. 双向循环神经网络
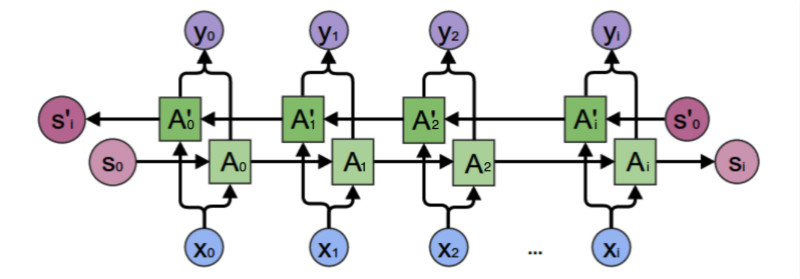
| 最终的输出值取决于和。其计算方法为: |
| \[\begin{align} \mathrm{y}_2=g(VA_2+V'A_2') \end{align}\] |
| 其中: |
| \[\begin{align} A_2&=f(WA_1+U\mathrm{x}_2)\\ A_2'&=f(W'A_3'+U'\mathrm{x}_2)\\ \end{align}\] |
| 正向计算时,隐藏层的值St与St-1有关;反向计算时,隐藏层的值S't与S't+1有关;最终的输出取决于正向和反向计算的加和。双向循环神经网络的计算方法: |
| \[\begin{align} \mathrm{o}_t&=g(V\mathrm{s}_t+V'\mathrm{s}_t')\\ \mathrm{s}_t&=f(U\mathrm{x}_t+W\mathrm{s}_{t-1})\\ \mathrm{s}_t'&=f(U'\mathrm{x}_t+W'\mathrm{s}_{t+1}')\\ \end{align}\] |
| 正向计算和反向计算不共享权重: U和U'、W和W'、V和V'都是不同的权重矩阵。 |
| ##### 1.1.3. 深度循环神经网络 |
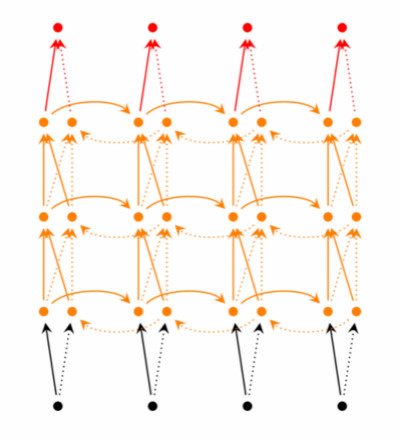
堆叠两个以上的隐藏层,就得到了深度循环神经网络。其计算方法为:
\[\begin{align} \mathrm{o}_t&=g(V^{(i)}\mathrm{s}_t^{(i)}+V'^{(i)}\mathrm{s}_t'^{(i)})\\ \mathrm{s}_t^{(i)}&=f(U^{(i)}\mathrm{s}_t^{(i-1)}+W^{(i)}\mathrm{s}_{t-1})\\ \mathrm{s}_t'^{(i)}&=f(U'^{(i)}\mathrm{s}_t'^{(i-1)}+W'^{(i)}\mathrm{s}_{t+1}')\\ ...\\ \mathrm{s}_t^{(1)}&=f(U^{(1)}\mathrm{x}_t+W^{(1)}\mathrm{s}_{t-1})\\ \mathrm{s}_t'^{(1)}&=f(U'^{(1)}\mathrm{x}_t+W'^{(1)}\mathrm{s}_{t+1}')\\ \end{align}\]
1.2. 循环神经网络的训练
- 循环神经网络的训练算法:BPTT
先前向传播,再反向传播,利用链式求导计算损失函数对每个权重的偏导数(梯度),然后再根据梯度下降公式更新权重w。
- 前向计算
\[\begin{align} \mathrm{s}_t=f(U\mathrm{x}_t+W\mathrm{s}_{t-1}) \end{align}\]
- 误差项的计算
BTPP算法将第l层t时刻的误差项值沿两个方向传播:
① 是沿空间传递到上一层网络,这部分只和权重矩阵U有关:
\[\begin{align} (\delta_t^{l-1})^T=&(\delta_t^l)^TUdiag[f'^{l-1}(\mathrm{net}_t^{l-1})] \end{align}\]
② 是沿时间线传递到初始时刻,这部分只和权重矩阵W有关:
\[\begin{align} \delta_k^T=&\delta_t^T\prod_{i=k}^{t-1}Wdiag[f'(\mathrm{net}_{i})] \end{align}\]
RNN在训练中很容易发生梯度爆炸和梯度消失(取决于大于1还是小于1),这导致训练时梯度不能在较长序列中一直传递下去,从而使RNN无法捕捉到长距离的影响。
2. 长短时记忆网络(LSTM)
原图和公式说明来自:- 零基础入门深度学习(6) - 长短时记忆网络
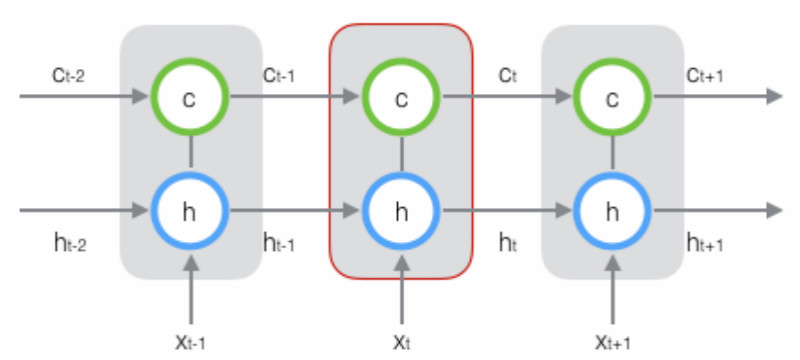
长短时记忆网络相对于普通循环神经网络,增加了一个状态c来保存长期的状态。
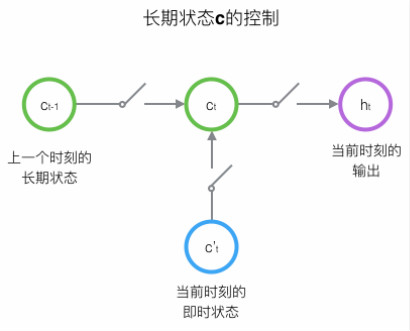
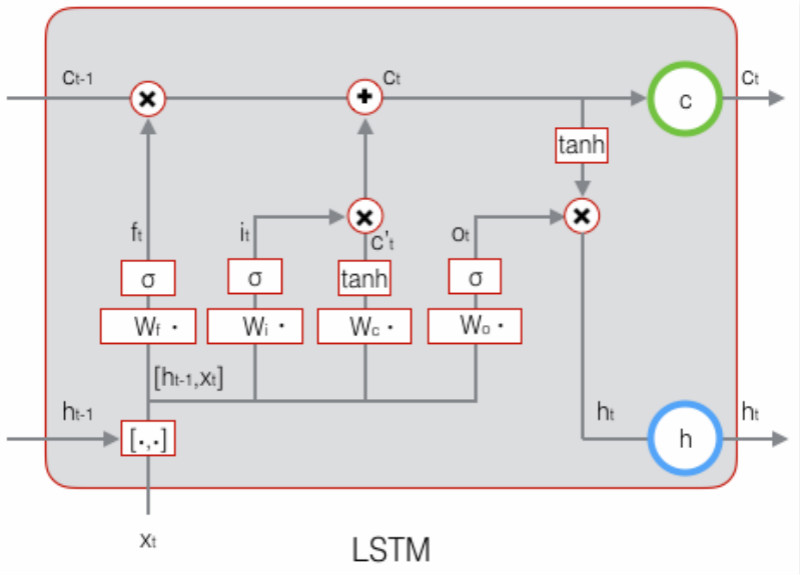
2.1. 长短时记忆网络的计算
\[\begin{align} g(\mathbf{x})=\sigma(W\mathbf{x}+\mathbf{b}) \end{align}\]
● 遗忘门(forget gate)决定了上一时刻的单元状态有多少保留到当前时刻:
\[\begin{align} \mathbf{f}_t=\sigma(W_f\cdot[\mathbf{h}_{t-1},\mathbf{x}_t]+\mathbf{b}_f) \end{align}\]
● 输入门(input gate)决定了当前时刻网络的输入有多少保存到单元状态:
\[\begin{align} \mathbf{i}_t=\sigma(W_i\cdot[\mathbf{h}_{t-1},\mathbf{x}_t]+\mathbf{b}_i) \end{align}\]
● 输出门(output gate)来控制单元状态有多少输出到LSTM的当前输出值:
\[\begin{align} \mathbf{\tilde{c}}_t=\tanh(W_c\cdot[\mathbf{h}_{t-1},\mathbf{x}_t]+\mathbf{b}_c) \end{align}\]
推荐阅读 - 强的笔记-我对LSTM的理解
2.2. 长短时记忆网络的训练
先前向传播,再反向传播,利用链式求导计算损失函数对每个权重的偏导数(梯度),然后再根据梯度下降公式更新权重w。
第l层t时刻的误差项值沿两个方向传播:
① 是沿空间传递到上一层网络,这部分只和权重矩阵U有关:
\[\begin{align} \frac{\partial{E}}{\partial{\mathbf{net}_t^{l-1}}}&=(\delta_{f,t}^TW_{fx}+\delta_{i,t}^TW_{ix}+\delta_{\tilde{c},t}^TW_{cx}+\delta_{o,t}^TW_{ox})\circ f'(\mathbf{net}_t^{l-1}) \end{align}\]
② 是沿时间线传递到初始时刻,这部分只和权重矩阵W有关:
\[\begin{align} \delta_k^T=\prod_{j=k}^{t-1}\delta_{o,j}^TW_{oh} +\delta_{f,j}^TW_{fh} +\delta_{i,j}^TW_{ih} +\delta_{\tilde{c},j}^TW_{ch} \end{align}\]
3. 基于TensorFlow的实现(RNN/LSTM with TF)
TensorFlow中的RNN的抽象基类“ RNNCell”,是实现RNN的基本单元。
Github - 源码阅读
● call方法
每个RNNCell都有一个call方法,使用方式是:(output, next_state) = call(input, state)。
每调用一次RNNCell的call方法,就相当于在时间上推进了一步。
假设有一个初始状态h0,还有输入x1,调用call(x1, h0)后就可以得到(output1, h1):
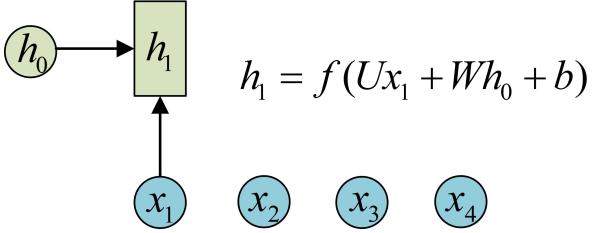
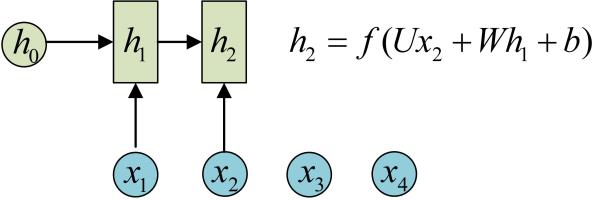
再调用一次call(x2, h1)就可以得到(output2, h2):
● 两个重要类变量
隐藏层的大小:state_size
输出层的大小:output_size
● 常用的三个子类
3.1. 单层LSTM例
1 | |
3.2. 一次执行多步
TensorFlow提供了一个tf.nn.dynamic_rnn函数,使用该函数就相当于调用了n次call函数。
1 | |
3.3. 堆叠RNNCell
即实现多层的RNN。将x输入第一层RNN的后得到隐层状态h,这个隐层状态就相当于第二层RNN的输入,第二层RNN的隐层状态又相当于第三层RNN的输入,以此类推。
1 | |
MultiRNNCell也是RNNCell的子类,因此也有call方法、state_size和output_size变量。同样可以通过tf.nn.dynamic_rnn来一次运行多步。
- Attention 版本问题
目前使用TensorFlow 1.2运行堆叠RNN的代码是:
1 | |
更早一些的版本中(比如TensorFlow 1.0.0),实现方式是:
1 | |
新版本按照这种的方式定义,就会引起报错。
阅读参考 - RNN入门:多层LSTM网络(四)
3.4. TF循环神经网络的实现例
Make TV scripts using RNN(Recurrent Neural Networks) and LSTM(Long Short-Term Memory) network. Generate a new TV script with the model from TV scripts training data sets.
RNN(Recurrent Neural Networks)及びLSTM(Long Short-Term Memory)を使用して、訓練データを用いたモデルを作成して、新しいテレビスクリプトを生成する。
程序实例 - Github Link
4. 词分析框架(Word Framework)
4.1. word2vec
单词嵌入模型(简称为 word2vec 模型)。将word映射成连续(高维)向量,这样通过训练,就可以把对文本内容的处理简化为K维向量空间中向量运算,而向量空间上的相似度可以用来表示文本语义上的相似度。
一般来说, word2vec输出的词向量可以被用来做NLP相关的工作,比如聚类、找同义词、词性分析等等。
有两种实现的架构,CBOW(Continuous Bag-Of-Words)模型以及Skip-gram模型:
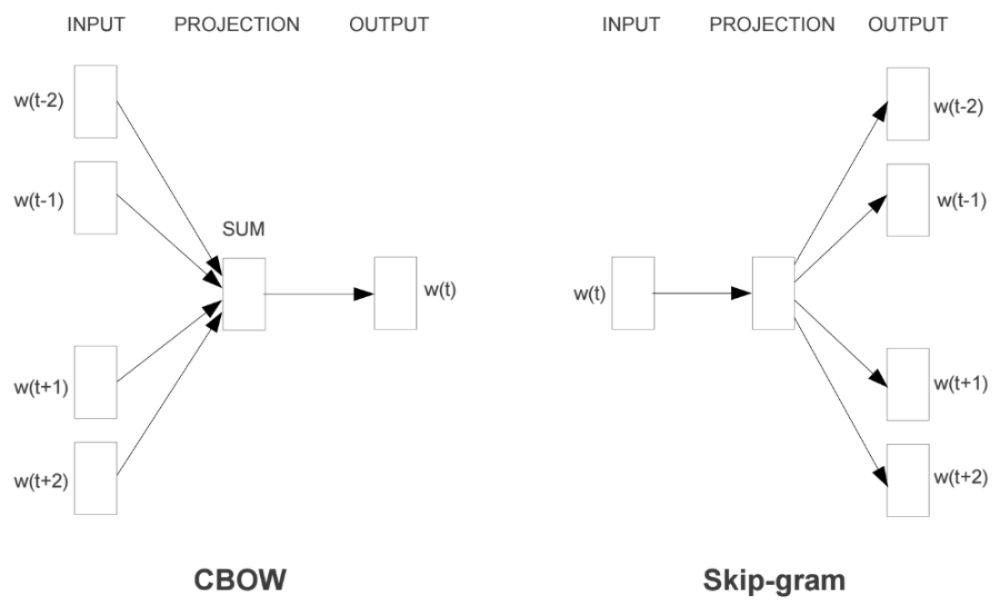
阅读链接 - word2vec入门基础
4.2. seq2seq
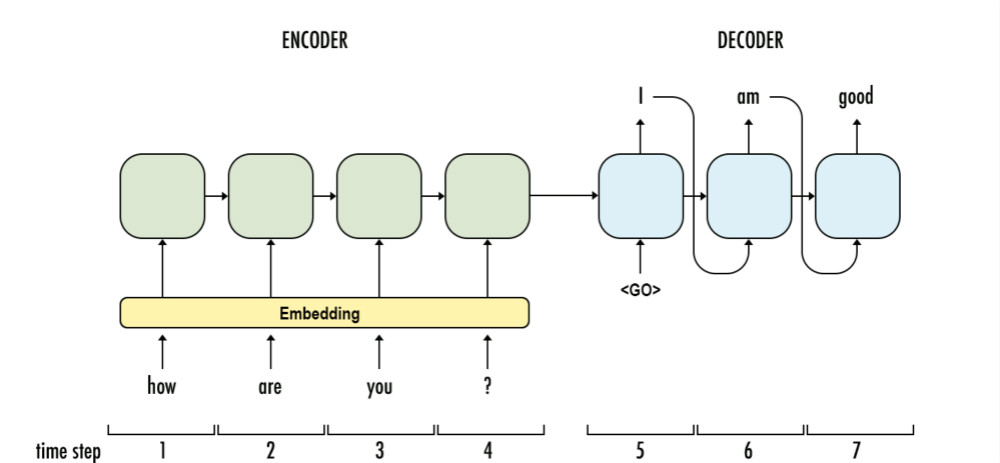
序列到序列模型(简称为 seq2seq 模型)。seq2seq模型就像一个翻译模型,输入是一个序列(比如一个英文句子),输出也是一个序列(比如该英文句子所对应的法文翻译)。
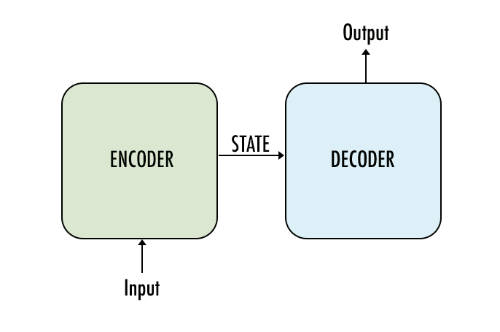
● 编码器:这是一个tf.nn.dynamic_rnn函数。
● 解码器:这是一个tf.contrib.seq2seq.dynamic_rnn_decoder函数。
阅读链接 - Seq2Seq的DIY简介
阅读链接 - 聊天机器人深度学习
阅读链接 - tensorflow-seq2seq-tutorials
● word2vec输出的是一个词向量,seq2seq输出的是一个词序列。
推荐阅读 - Deep Learning for Chatbots, Part 1
推荐阅读 - 《安娜卡列尼娜》文本生成
推荐阅读 - LSTMで夏目漱石ぽい文章の生成