Deep learning笔记5-GAN生成式对抗网络
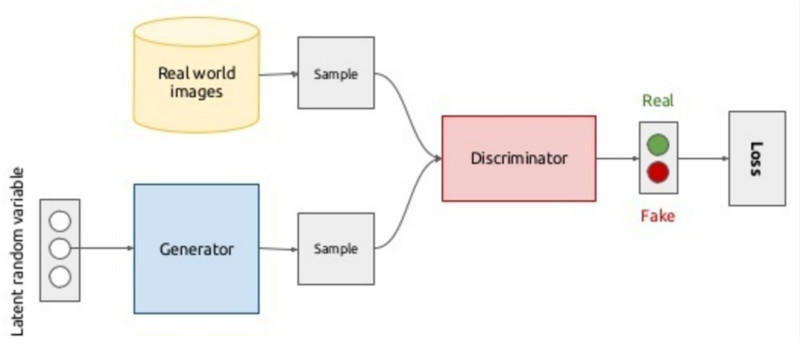
1. 生成式对抗网络(GAN)
GAN(Generative Adversarial Network)的思想:生成器和鉴别器两个网络彼此博弈。
● 生成器的目标是生成一个对象,并使其看起来和真的一样。
● 鉴别器的目标就是找到生成出的结果和真实图像之间的差异。
内容部分来自:はじめてのGAN
訓練データを学習し、それらのデータと似たような新しいデータを生成するモデルのことを生成モデルと呼びます。別の言い方をすると、訓練データの分布と生成データの分布が一致するように学習していくようなモデルです。
GANではgeneratorとdiscriminatorという2つのネットワークが登場します。Generatorは訓練データと同じようなデータを生成しようとします。一方、discriminatorはデータが訓練データから来たものか、それとも生成モデルから来たものかを識別します。
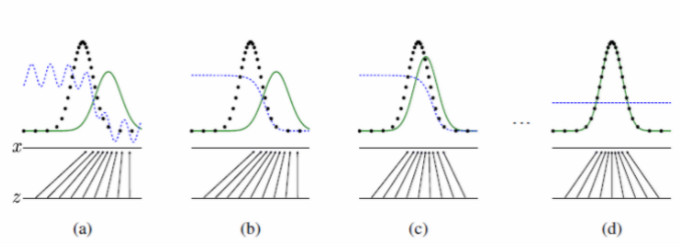
如上图所示,生成对抗网络会训练并更新判别分布,更新判别器后就能将数据真实分布从生成分布中判别出来。经过若干次训练后,如果 G 和 D 有足够的复杂度,那么它们就会到达一个均衡点。这个时候生成器的概率密度函数等于真实数据的概率密度函数,也即生成的数据和真实数据是一样的。在均衡点上 D 和 G 都不能得到进一步提升,并且判别器无法判断数据到底是来自真实样本还是伪造的数据,即 D(x)= 1/2。
GAN学习的表征可用于多种应用,包括图像合成、语义图像编辑、风格迁移、图像超分辨率技术和分类。
eg. ベッドルームの画像のデータセットを使って学習した結果です。一見本物と見間違ってしまいそうなレベルの画像を生成できていることが分かります。

eg. Word2Vecという単語ベクトルで「王様」-「男」+「女」=「女王」という演算ができることは有名ですが、GANにおける入力であるzzベクトルを使っても同様の演算を行うことができます。下の例では、「サングラスをかけた男」-「男」+「女」=「サングラスをかけた女」という演算を行っています。

GAN的类别 - 内容来自:生成对抗网络综述:从架构到训练技巧
1.1. 全连接 GAN
首个 GAN 架构在生成器与鉴别器上皆使用全连接神经网络。这种架构类型被应用于相对简单的图像数据库,即 MNIST(手写数字)、CIFAR-10(自然图像)和多伦多人脸数据集(TFD)。
1.2. 卷积 GAN
● LAPGAN拉普拉斯金字塔形对抗网络(Laplacian pyramid GAN)
真值图像本身被分解成拉普拉斯金字塔(Laplacian pyramid),并且条件性卷积 GAN 被训练在给定上一层的情况下生成每一层。
● DCGAN(Deep Convolutional GAN)
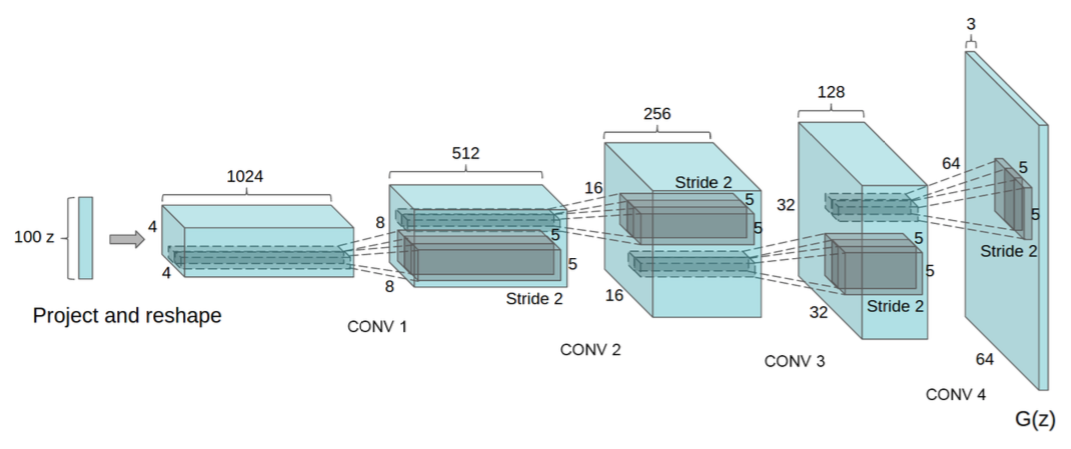
DCGAN允许训练一对深度卷积生成器和判别器网络。在训练中使用带步长的卷积(strided convolution)和小步长卷积(fractionally-strided convolution),并在训练中学习空间下采样和上采样算子。
1.3. 条件 GAN
通过将生成器和判别器改造成条件类(class-conditional)而将(2D)GAN 框架扩展成条件设置。条件 GNN 的优势在于可以对多形式的数据生成提供更好的表征。条件 GAN 和 InfoGAN[16] 是平行的,它可以将噪声源分解为不可压缩源和一个「隐编码」(latent code),并可以通过最大化隐编码和生成器之间的交互信息而发现变化的隐藏因子。这个隐编码可用于在完全无监督的数据中发现目标类,即使这个隐编码是不明确的。由 InfoGAN 学到的表征看起来像是具备语义特征的,可以处理图貌中的复杂纠缠因素(包括姿势变化、光照和面部图像的情绪内容)。
1.4. GAN 推断模型
GAN 的初始形式无法将给定的输入 x 映射为隐空间中的向量(在 GAN 的文献中,这通常被称为一种推断机制)。人们提出了几种反转预训练 GAN 的生成器的技术,比如各自独立提出的对抗性学习推断(Adversarially Learned Inference,ALI)和双向 GAN(Bidirectional GANs),它们能提供简单而有效的扩展,通过加入一个推断网络,使判别器共同测试数据空间和隐空间。
这种形式下的生成器由两个网络组成:即编码器(推断网络)和解码器。它们同时被训练用于欺骗判别器。而判别器将接收到一个向量对(x,z),并决定其是否包含一个真实图像以及其编码,或者一个生成的图像样本以及相关的生成器的隐空间输入。
1.5. AAE 对抗自编码器
自编码器是由编码器和解码器组成的网络,学习将数据映射到内部隐表征中,再映射出来,即从数据空间中学习将图像(或其它)通过编码映射到隐空间中,再通过解码从隐空间映射回数据空间。这两个映射形成了一种重构运算,而这两个映射将被训练直到重构图像尽可能的接近初始图像。
2. 生成式对抗网络的训练(GAN Training)
生成对抗网络(GAN)提供了一种不需要大量标注训练数据就能学习深度表征的方式。它们通过反向传播算法分别更新两个网络以执行竞争性学习而达到训练目的。
2.1. 训练
训练的代价由一个价值函数 V(G,D) 评估,其包含了生成器和判别器的参数。
训练过程可表示如下:
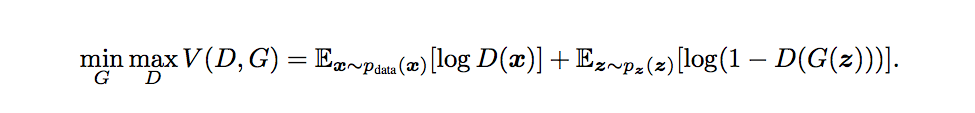
训练过程中,其中一个模型的参数被更新,同时另一个模型的参数固定不变。
算法描述:Goodfellow et al. (2014) より引用

推荐阅读 - 机器之心GitHub项目:GAN完整理论推导与实现
推荐阅读 - はじめてのGAN
2.2. 训练技巧
用于图像生成的 GAN 训练的第一个重大改进是 Radford et al.提出的 DCGAN 架构。具体到训练中,研究者推荐在两种网络中使用批量归一化,以稳定深层模型中的训练。另一个建议是最小化用于提升深层模型训练可行性的全连接层的数量。最后,Radford et al.认为在判别器中间层使用leaky ReLU激活函数的性能优于使用常规的 ReLU 函数。
● 特征匹配稍稍改变生成器的目标,以增加可获取的信息量。
● 小批量判别(mini-batch discrimination)向判别器额外添加输入,该特征对小批量中的给定样本和其他样本的距离进行编码,防止模式崩溃(mode collapse),因为判别器能够轻易判断生成器是否生成同样的输出。
● 启发式平均(heuristic averaging),如果网络参数偏离之前值的运行平均值,则会受到惩罚,这有助于收敛到平衡态。
● 虚拟批量归一化(virtual batch normalization),可减少小批量内样本对其他样本的依赖性,方法是使用训练开始就确定的固定参考小批量(reference mini-batch)样本计算归一化的批量统计(batch statistics)。
● 单边标签平滑(one-sided label smoothing)将判别器的目标从 1 替换为 0.9,使判别器的分类边界变得平滑,从而阻止判别器过于自信,为生成器提供较差的梯度。
3. 基于TensorFlow的Keras实现(Keras)
内容来自:机器之心GitHub项目:GAN完整理论推导与实现
● 生成模型
首先需要定义一个生成器 G,该生成器需要将输入的随机噪声变换为图像。以下是定义的生成模型,该模型首先输入有 100 个元素的向量,该向量随机生成于某分布。随后利用两个全连接层接连将该输入向量扩展到 1024 维和 12877 维,后面就开始将全连接层所产生的一维张量重新塑造成二维张量,即 MNIST 中的灰度图。我们注意到该模型采用的激活函数为 tanh,所以也尝试过将其转换为 relu 函数,但发现生成模型如果转化为 relu 函数,那么它的输出就会成为一片灰色。
由全连接传递的数据会经过几个上采样层和卷积层,我们注意到最后一个卷积层所采用的卷积核为 1,所以经过最后卷积层所生成的图像是一张二维灰度图像。
1 | |
● 判别模型
判别模型相对来说就是比较传统的图像识别模型,前面我们可以按照经典的方法采用几个卷积层与最大池化层,而后再展开为一维张量并采用几个全连接层作为架构。我们尝试了将 tanh 激活函数改为 relu 激活函数,在前两个 epoch 基本上没有什么明显的变化。
1 | |
● 拼接
前面定义的是可生成图像的模型 G,而我们在训练生成模型时,需要固定判别模型 D 以极小化价值函数而寻求更好的生成模型,这就意味着我们需要将生成模型与判别模型拼接在一起,并固定 D 的权重以训练 G 的权重。下面就定义了这一过程,我们先添加前面定义的生成模型,再将定义的判别模型拼接在生成模型下方,并且我们将判别模型设置为不可训练。因此,训练这个组合模型才能真正更新生成模型的参数。
1 | |
● 训练
以下训练过程可简述为:
- 加载 MNIST 数据
- 将数据分割为训练与测试集,并赋值给变量
- 设置训练模型的超参数
- 编译模型的训练过程
- 在每一次迭代内,抽取生成图像与真实图像,并打上标注
- 随后将数据投入到判别模型中,并进行训练与计算损失
- 固定判别模型,训练生成模型并计算损失,结束这一次迭代
1 | |