Reinforcement Learning笔记4-Monte Carlo
Bellman最优解策略 - 蒙特卡罗方法(Monte Carlo Methods)
蒙特卡罗方法又叫统计模拟方法,它使用随机数(或伪随机数)来解决计算的问题,是一类重要的数值计算方法。该方法的名字来源于世界著名的赌城蒙特卡罗,而蒙特卡罗方法正是以概率为基础的方法。
一个简单的例子可以解释蒙特卡罗方法,假设我们需要计算一个不规则图形的面积,那么图形的不规则程度和分析性计算(比如积分)的复杂程度是成正比的。而采用蒙特卡罗方法是怎么计算的呢?首先你把图形放到一个已知面积的方框内,然后假想你有一些豆子,把豆子均匀地朝这个方框内撒,散好后数这个图形之中有多少颗豆子,再根据图形内外豆子的比例来计算面积。当你的豆子越小,撒的越多的时候,结果就越精确。
强化学习方法分类:
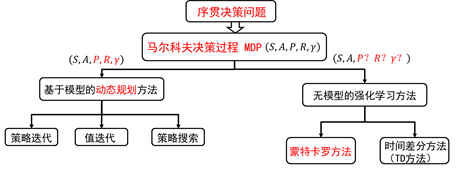
若已知模型时,马尔科夫决策过程可以利用动态规划的方法来解决。
无模型的强化学习算法主要包括蒙特卡罗方法和时间差分方法。
1. 蒙特卡罗方法(Monte Carlo)
蒙特卡罗方法仅仅需要经验就可以求解最优策略,这些经验可以在线获得或者根据某种模拟机制获得。
要注意的是,仅将蒙特卡罗方法定义在episode task上,所谓的episode task就是指不管采取哪种策略π,都会在有限时间内到达终止状态并获得回报的任务。比如玩棋类游戏,在有限步数以后总能达到输赢或者平局的结果并获得相应回报。
那么什么是经验呢?经验其实就是训练样本。比如在初始状态s,遵循策略π,最终获得了总回报R,这就是一个样本。如果我们有许多这样的样本,就可以估计在状态s下,遵循策略π的期望回报,也就是状态值函数Vπ(s)了。蒙特卡罗方法就是依靠样本的平均回报来解决增强学习问题的。
2. 蒙特卡罗策略改进(Monte Carlo Policy Evalution)
内容来自:强化学习入门 第三讲 蒙特卡罗方法
探索的必要性:状态值函数和行为值函数的计算实际上是计算返回值的期望。动态规划的方法是利用模型对该期望进行计算。在没有模型时,我们可以采用蒙特卡罗的方法计算该期望,即利用随机样本来估计期望。在计算值函数时,蒙特卡罗方法是利用 经验平均 代替随机变量的期望。
如何获得充足的经验是无模型强化学习的核心所在。
在动态规划方法中,为了保证值函数的收敛性,算法会对状态空间中的状态进行逐个扫描。无模型的方法充分评估策略值函数的前提是每个状态都能被访问到。因此,在蒙特卡洛方法中必须采用一定的方法保证每个状态都能被访问到。其中一种方法是探索性初始化。
探索性初始化:是指每个状态都有一定的几率作为初始状态。在给出基于探索性初始化的蒙特卡罗方法前,我们还需要给出策略改进方法,以及便于进行迭代计算的平均方法。
蒙特卡罗策略改进:蒙特卡罗方法利用经验平均对策略值函数进行估计。当值函数被估计出来后,对于每个状态s ,通过最大化动作值函数,来进行策略的改进。即:
\[\begin{align} \pi\left(s\right)=\underset{a}{arg\max\textrm{\ }}q\left(s,a\right) \end{align}\]
递增计算平均的方法:


在探索性初始化中,迭代每一幕时,初始状态是随机分配的,这样可以保证迭代过程中每个状态行为对都能被选中。它蕴含着一个假设,即:假设所有的动作都被无限频繁选中。对于这个假设,有时很难成立,或无法完全保证。
● 如何保证初始状态不变的同时,又能保证报个状态行为对可以被访问到?
答案是:精心地设计你的探索策略,以保证每个状态都能被访问到。
● 可是如何精心地设计探索策略?符合要求的探索策略是什么样的?
答案是:策略必须是温和的,即对所有的状态s 和a 满足:
\[\begin{align} \pi\left(a|s\right)>0 \end{align}\]
也就是说,温和的探索策略是指在任意状态下,采用动作集中每个动作的概率都大于零。典型的温和策略是
\[\begin{align} \varepsilon -soft \end{align}\]
即:

根据探索策略(行动策略)和评估的策略是否是同一个策略,蒙特卡罗方法又分为on-policy和off-policy.
● 若行动策略和评估及改善的策略是同一个策略,称之为on-policy,可翻译为同策略。
● 若行动策略和评估及改善的策略是不同的策略,称之为off-policy,可翻译为异策略。
まとめ: 以上大概讲解了如何利用MC的方法估计值函数。跟基于动态规划的方法相比,基于MC的方法只是在值函数估计上有所不同。两者在整个框架上是相同的,即对当前策略进行评估,然后利用学到的值函数进行策略改进。
3. 蒙特卡罗(Monte Carlo)VS 拉斯维加斯(Las Vegas)
内容来自:知乎:蒙特卡罗算法是什么?- 孙天齐回答
这里把随机算法分成两类:
蒙特卡罗算法:采样越多,越近似最优解;
拉斯维加斯算法:采样越多,越有机会找到最优解;
● 举个例子,假如筐里有100个苹果,让我每次闭眼拿1个,挑出最大的。于是我随机拿1个,再随机拿1个跟它比,留下大的,再随机拿1个……我每拿一次,留下的苹果都至少不比上次的小。拿的次数越多,挑出的苹果就越大,但我除非拿100次,否则无法肯定挑出了最大的。这个挑苹果的算法,就属于蒙特卡罗算法——尽量找好的,但不保证是最好的。
● 而拉斯维加斯算法,则是另一种情况。假如有一把锁,给我100把钥匙,只有1把是对的。于是我每次随机拿1把钥匙去试,打不开就再换1把。我试的次数越多,打开(最优解)的机会就越大,但在打开之前,那些错的钥匙都是没有用的。这个试钥匙的算法,就是拉斯维加斯的——尽量找最好的,但不保证能找到。
这两个词并不深奥,它只是概括了随机算法的特性,算法本身可能复杂,也可能简单。这两个词本身是两座著名赌城,因为赌博中体现了许多随机算法,所以借过来命名。这两类随机算法之间的选择,往往受到问题的局限。如果问题要求在有限采样内,必须给出一个解,但不要求是最优解,那就要用蒙特卡罗算法。反之,如果问题要求必须给出最优解,但对采样没有限制,那就要用拉斯维加斯算法。
对于机器围棋程序而言,因为每一步棋的运算时间、堆栈空间都是有限的,而且不要求最优解,所以ZEN涉及的随机算法,肯定是蒙特卡罗式的。机器下棋的算法本质都是搜索树,围棋难在它的树宽可以达到好几百(国际象棋只有几十)。在有限时间内要遍历这么宽的树,就只能牺牲深度(俗称“往后看几步”),但围棋又是依赖远见的游戏,甚至不仅是看“几步”的问题。所以,要想保证搜索深度,就只能放弃遍历,改为随机采样——这就是为什么在没有MCTS(蒙特卡罗搜树)类的方法之前,机器围棋的水平几乎是笑话。而采用了MCTS方法后,搜索深度就大大增加了。