Reinforcement Learning笔记5-Temporal Diff
Bellman最优解策略 - 时间差分法(Temporal Difference)
蒙特卡洛算法需要采样完成一个轨迹之后,才能进行值估计(value estimation),这样蒙特卡洛速度很慢,主要原因在于蒙特卡洛没有充分的利用强化学习任务的 MDP 结构。但是,TD 充分利用了 “MC”和 动态规划的思想,做到了更加高效率的免模型学习。
强化学习算法可以分为在同策略(on-policy)和异策略(off-policy)两类:
若行动策略和评估及改善的策略是同一个策略,称之为on-policy,可翻译为同策略。
若行动策略和评估及改善的策略是不同的策略,称之为off-policy,可翻译为异策略。
● Q-learning属于离策略(off-policy)算法。
● Sarsa属于在策略(on-policy)算法。
本文内容来自知乎 - 莫烦 ,以小时候写作业为例子,看看TD是如何来决策:
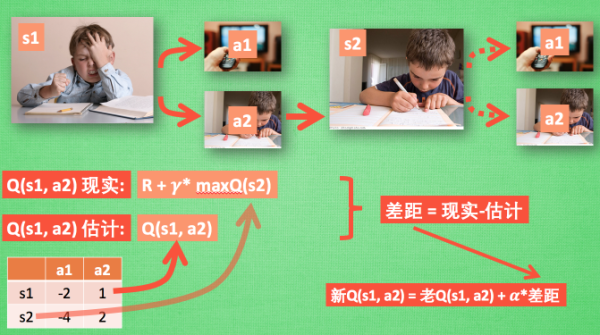
1. Q-learning
● 感性认识:内容来自 - 什么是 Q-Learning - 莫烦
1.1. Q-Learning 决策

1.2. Q-Learning 更新
1.3. Q-Learning 整体算法

1.4. Q-Learning 中的 Lambda

DQN(Deep Q-learning)
Q-learning中因为需要下一状态的所有动作的最大Q,loss的也有个特点:网络要多前向计算一次,才能得到下一状态的所有动作的Q。也是因为这个loss的原因,这里的DQN等于说是把CNN用作生成Q的一个函数。原来的质量表达Q是个矩阵,参数少,现在的用深度网络,就叫深度质量网络(DQN)。
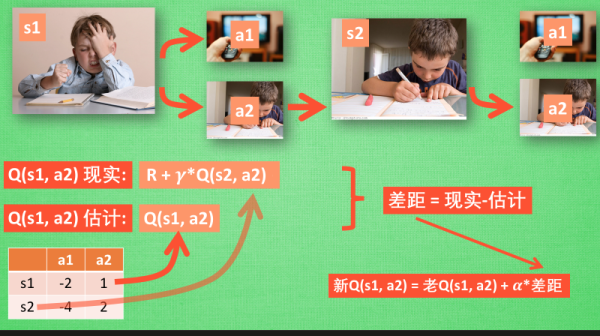
2. Sarsa
● 感性认识:内容来自 - 什么是 Sarsa - 莫烦
sarsa算法估计的是动作值函数(Q函数)而非状态值函数。
2.1. Sarsa 决策

Sarsa 的决策部分和 Q-learning 一模一样, 因为使用的是 Q 表的形式决策, 所以在 Q 表中挑选值较大的动作值施加在环境中来换取奖惩. 但是不同的地方在于 Sarsa 的更新方式是不一样的。
2.2. Sarsa 更新行为准则
3. Sarsa VS Q-learning
内容来自:什么是 Sarsa - 莫烦

从算法来看, 这就是他们两最大的不同之处了. 因为 Sarsa 是说到做到型, 所以我们也叫他 on-policy在线学习, 学着自己在做的事情. 而 Q learning 是说到但并不一定做到, 所以它也叫作 Off-policy, 离线学习. 而因为有了 maxQ, Q-learning 也是一个特别勇敢的算法。
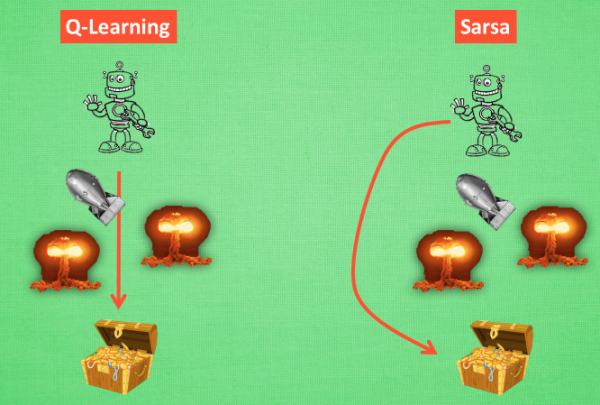
为什么说他勇敢呢, 因为 Q learning 机器人 永远都会选择最近的一条通往成功的道路, 不管这条路会有多危险. 而 Sarsa 则是相当保守, 他会选择离危险远远的, 拿到宝藏是次要的, 保住自己的小命才是王道. 这就是使用 Sarsa 方法的不同之处。
● 开源推荐:OpenAI Gym
4. 时间差分法(TD)VS 蒙特卡罗( MC)
内容来自:知乎:强化学习中时间差分(TD)和蒙特卡洛(MC)方法各自的优劣?- 远方的梦回答
TD对应的sarsa/qlearning和MC对应的control算法进行比较:
● 1. MC计算量更大,更新缓慢。
可以这样理解:对MC而言,其return如下:
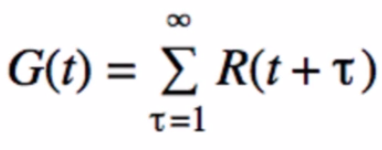
所以MC必须在整轮episode迭代结束后进行更新(也就是一盘围棋要下完才更新一次),而TD(0)在下一个状态s(t+1)后就可以进行更新,其return如下:
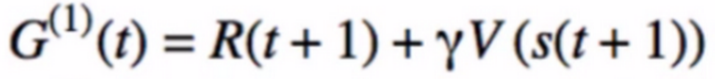
● 2.MC不能用于continuous task(比如倒立摆), 而TD(0)可以:理由同上。
● 3.相反于第二点,MC能用于一些围棋之类的规划较深的任务。
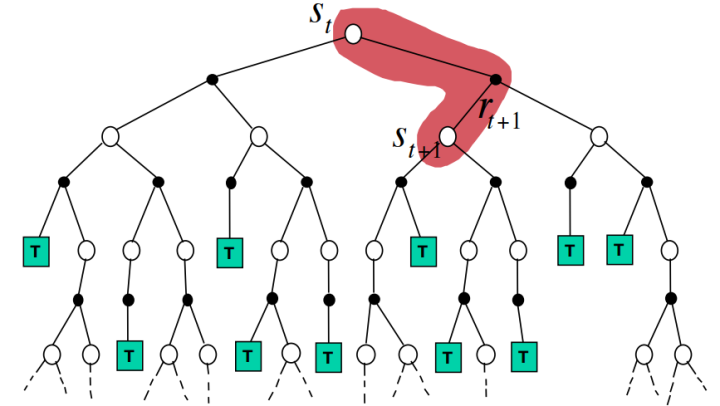
这个“深”字体现在:先阶段某个action对以后未来的action决策都有较大的影响(象棋,围棋之类的,想必深有体会)。而对于倒立摆这种问题,我现在让它向左的这个决策对于其1分钟后而言,其实基本没什么关系。参考下面两张图:
蒙特卡罗( MC):
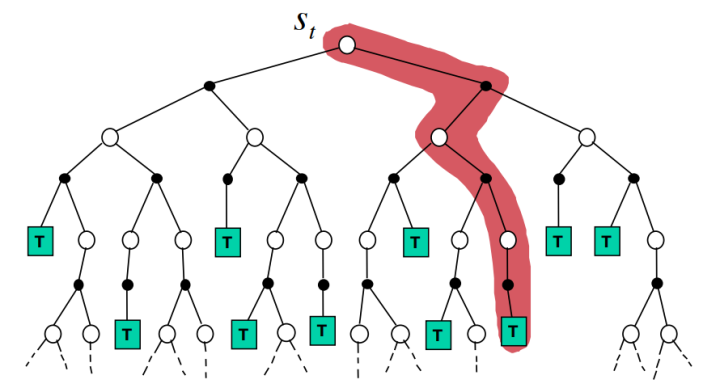
时间差分法(TD):